ACTUALIZACIÓN 25 de mayo de 2021: el "Server-Side Tagging" de Google Tag Manager evoluciona y esquivar los adblockers es cada vez más fácil. He añadido la sección "Un paso por delante de los adblockers" al artículo.
Google Tag Manager, el caballo de Troya de los equipos de marketing
Google Tag Manager es un TMS (Tag Management System, sistema de gestión de etiquetas): permite a los equipos de marketing añadir rastreadores a un sitio web o una aplicación sin tener que recurrir a los desarrolladores. A través de una interfaz web, estos equipos pueden decidir:
- Qué rastreadores activar (analítica, pruebas A/B, atribución, etc.).
- En qué condiciones activarlos (categorías de páginas, características del usuario, etc.).
- Qué datos transmitir a estas herramientas de terceros (características del usuario, datos de navegación, variables presentes en la página, etc.).
No es el único (podemos citar por ejemplo Segment, la francesa TagCommander o Matomo Tag Manager) pero Google Tag Manager es ultra dominante:
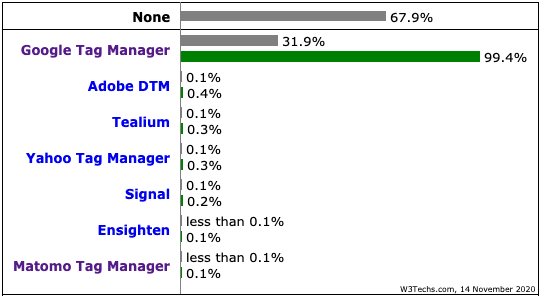
Google Tag Manager está presente en el 31,9% del top 10 millones de sitios web de Alexa, según W3Techs, pero sobre todo Google Tag Manager tiene una cuota de mercado del 99,4% entre los TMS (¡!)
¿Cómo ha podido Google volver a imponerse? Al igual que con Google Analytics, la versión estándar de Google Tag Manager es gratuita (las soluciones del mercado suelen ser de pago), está muy bien integrada con las demás soluciones de Google y está bien hecha.
Rastreadores que ya no se invocan desde tu navegador
El pasado mes de agosto, Google anunció una nueva versión de Google Tag Manager, llamada Server-Side Tagging. Aquí tienes un esquema de Google que explica cómo funciona Google Tag Manager en su versión Client-Side Tagging (la versión "histórica"):
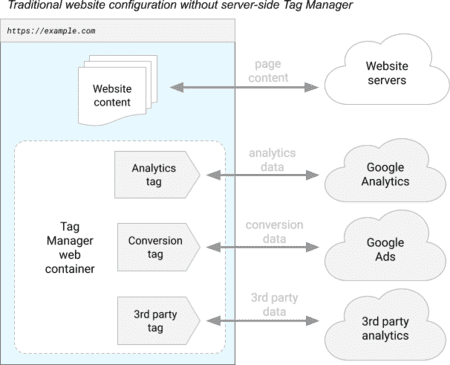
Google Tag Manager permitirá activar varios rastreadores de terceros (en el diagrama: Google Analytics, Google Ads y una herramienta de análisis), directamente en tu navegador.
En la nueva versión Server-Side, los rastreadores de terceros ya no se ejecutan desde tu navegador, sino desde un servidor "proxy" llamado "Server container" en el diagrama de abajo (y alojado en Google):
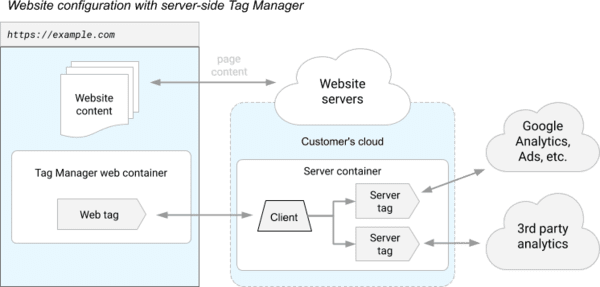
La biblioteca JavaScript (llamada "Tag Manager web container" en el diagrama) sigue ejecutándose en tu navegador para recopilar tus interacciones y tus datos personales, pero la ejecución de los distintos rastreadores de terceros tiene lugar del lado del servidor.
Ten en cuenta que esta nueva versión también se aplica a las aplicaciones y a la recopilación de datos "offline" (para transmitir compras en la tienda, por ejemplo):
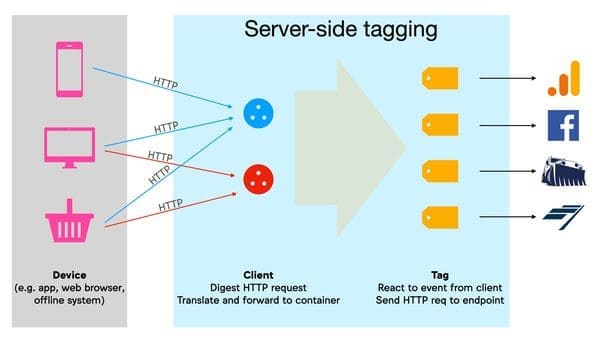
Esquema del blog de Simo Ahava: del lado del servidor, los "Clients" se encargan de traducir las solicitudes HTTP recibidas en "events", y los "Tags" reaccionan a esos eventos para enviar "hits" a las empresas de marketing de terceros.
Esta lógica de activar los rastreadores de terceros del lado del servidor cambia las reglas del juego. Simo Ahava detalló los distintos impactos en un excelente artículo; por mi parte, resumiré las ventajas y me detendré en los problemas para tu privacidad (operar del lado del servidor puede permitir eludir tus decisiones y filtrar tus datos personales, sin ser descubierto).
Mejor experiencia de usuario
En la mayoría de los sitios web, la cantidad de bibliotecas de JavaScript cargadas por terceros (para análisis, publicidad, pruebas A/B, etc.) es impresionante. Cargar y ejecutar estas bibliotecas suele ser la causa principal de una mala experiencia de usuario: lentitud del sitio y falta de interactividad.
Consecuencias para los sitios web que ofrecen una mala experiencia de usuario: internautas menos satisfechos, que abandonarán directamente la navegación o no volverán.
Aquí tienes un ejemplo con Le Bon Coin, que carga un número incalculable de bibliotecas JavaScript:
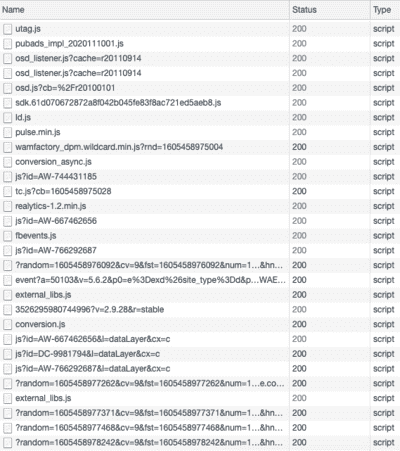
Una pequeña parte de los scripts JavaScript cargados en la página de inicio de Le Bon Coin, que filtra tus datos personales a numerosos terceros.
En el mejor de los casos, el sitio web solo instalará una única biblioteca JavaScript (como los eventos pueden ser muy distintos entre herramientas que no persiguen los mismos objetivos, el sitio web utilizará a veces más de una biblioteca). Esta podrá ser la de Google Tag Manager, pero no necesariamente: es posible crear tu propia biblioteca o utilizar otras bibliotecas del mercado como Snowplow, Matomo, AT Internet, etc.
Le corresponde luego a esta biblioteca enviar los "hits" con los parámetros requeridos durante las interacciones clave. Después, el "client" del contenedor de servidor deberá traducir esos "hits" en eventos, que serán leídos por los "Tags", que a su vez enviarán "hits" a las empresas de marketing de terceros. Ten en cuenta que, si la biblioteca JavaScript instalada en el sitio la proporciona Google, el "client" ya viene preconfigurado en Google Tag Manager. Si el sitio web utiliza otra biblioteca, tendrá que crear su propio "client" en Google Tag Manager (ejemplo con AT Internet), a la espera de que haya "clients" preconfigurados para las principales bibliotecas de seguimiento JavaScript.
La ventaja, por tanto: una sola biblioteca de seguimiento JavaScript instalada en el sitio web y un único "flujo" de datos procedente del navegador; el usuario debería notar la diferencia.
Mejor control sobre los datos transmitidos a terceros
Tener un "proxy" del lado del servidor permite controlar los datos transmitidos a terceros (mucho más difícil cuando los rastreadores los ejecuta directamente el navegador del usuario):
- Por defecto, y a diferencia de la versión "client-side", la dirección IP y el User-Agent (nombre del navegador, versión, sistema operativo, idioma, etc.) del usuario no se filtran (lo que evita identificar al usuario mediante "fingerprinting"). El editor que utiliza la versión Server-Side Tagging de Google Tag Manager puede decidir transmitir esta información a terceros, pero no es automático.
- A menudo, información personal se filtra a terceros a través de parámetros de URL (lee, por ejemplo, el artículo "Google Tag Manager Server-Side — How To Manage Custom Vendor Tags"); el Server-Side Tagging permite evitarlo.
- En general, el editor controla los datos personales y las cookies que su "proxy" envía a terceros (lee la documentación técnica de Google; fíjate, por ejemplo, en los métodos get_cookies y set_cookies). Puede, por tanto, "limpiar" la información y enviar a terceros solo lo estrictamente necesario.
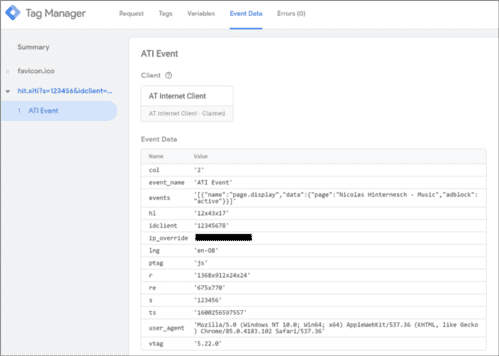
Ejemplo de un hit de AT Internet "visto" por el servidor "proxy": el sitio web puede decidir no transmitir a AT Internet la dirección IP ni el User-Agent del usuario.
Un sitio web más seguro
Configurar una Content-Security Policy (CSP) permite a un editor protegerse mejor frente a distintos tipos de amenazas, entre ellas los ataques XSS (Cross-Site Scripting) y las inyecciones de contenido. Al añadir una cabecera a las respuestas del servidor web, el sitio puede indicar a los navegadores qué recursos (scripts, CSS, etc.) están permitidos.
Aquí tienes un ejemplo de CSP documentado por Google:
Content-Security-Policy: script-src 'self' https://apis.google.com.
Lo que significa: el navegador solo tiene permiso para ejecutar los scripts que provienen directamente del sitio consultado ('self') o de apis.google.com. Y así es como reaccionará tu navegador si un script malicioso intenta ejecutarse desde el sitio consultado:
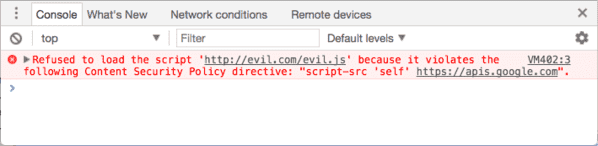
El script evil.js no está alojado en el sitio consultado ni en apis.google.com: su ejecución la bloquea el navegador.
Al reducir notablemente los dominios de terceros autorizados a ejecutar código JavaScript, la CSP se vuelve más robusta.
Si bien el Server-Side Tagging tiene ventajas para los usuarios que consienten la vigilancia de marketing (rapidez, seguridad), pone en peligro las protecciones de los usuarios que no la consienten.
Esquivar las protecciones del navegador
El servidor "proxy" está alojado en la nube de Google (instancia de App Engine), pero Google aconseja vincular el dominio de App Engine a un subdominio del sitio de sus clientes (sin explicar los motivos):
El despliegue de etiquetado del lado del servidor predeterminado se aloja en un dominio de App Engine. Te recomendamos que modifiques el despliegue para utilizar en su lugar un subdominio de tu sitio web.
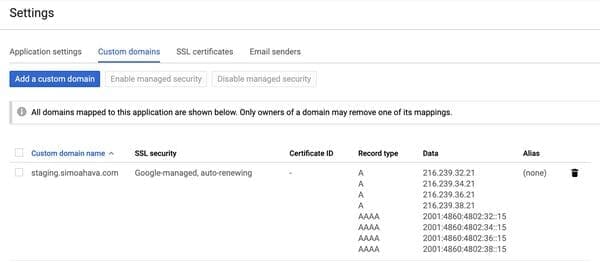
El vínculo entre el dominio de App Engine y el subdominio del cliente, documentado por Google.
Google no recomienda un registro DNS de tipo CNAME (alias), sino un registro DNS de tipo A o AAAA, vinculado directamente a las direcciones IP de Google App Engine, que hace de alojamiento. Por tanto, los navegadores consideran el servidor "proxy" como first-party, y las consecuencias son importantes.
En particular, las cookies depositadas por el servidor "proxy" no son cookies de terceros, ni cookies creadas mediante JavaScript, ni cookies depositadas por un dominio CNAME. Por tanto, quedan autorizadas, sin restricciones:
- Safari, mediante Intelligent Tracking Prevention (ITP), restringe a 7 días la vida útil de las cookies creadas en JavaScript (por ejemplo, las cookies first-party creadas por Google Analytics). Gracias al servidor "proxy", los rastreadores de terceros sortean ahora esta limitación.
- De nuevo Safari, mediante ITP, restringe ahora a 7 días las cookies depositadas a través de un dominio CNAME. Gracias al servidor "proxy", los rastreadores de terceros no se ven afectados por esta limitación.
- Brave, por su parte, bloquea las solicitudes CNAME hacia rastreadores conocidos. También gracias al servidor "proxy", los rastreadores de terceros esquivan este bloqueo.
Esquivar los adblockers
Tu adblocker (uBlock Origin en Firefox, por ejemplo), tu bloqueador de contenido (Firefox Focus o AdGuard en iOS, por ejemplo) o tu bloqueador DNS (NextDNS, por ejemplo) funciona en tu dispositivo. Así puede detectar los rastreadores de terceros y bloquearlos antes de que se filtren tus datos personales.
Nada de esto ocurre con la versión Server-Side Tagging de Google Tag Manager: las filtraciones de datos personales se producen desde el servidor proxy del cliente (alojado en la nube de Google) hacia los terceros. Ya no tienes, por tanto, ningún control para evitar estas fugas.
Podrías pensar: basta con bloquear la primera llamada, la de tu navegador hacia la biblioteca JavaScript encargada de recopilar los datos y comunicarse con el servidor "proxy". Solo que esta biblioteca JavaScript puede perfectamente servirse desde el propio dominio del sitio web (y no desde un dominio de Google, por ejemplo). Además, Google ya recomienda a sus clientes cambiar sus scripts gtag.js para indicar el dominio del servidor proxy. Esta operación ya hace que el bloqueo por nombre de dominio deje de funcionar.
Todas las bibliotecas de seguimiento de Google (gtag.js, analytics.js, pero también gtm.js, la biblioteca "avanzada" de Google a cargo de Google Tag Manager) pueden alojarse en un dominio propio.
Si bien gtag.js o gtm.js son bibliotecas JavaScript cuyos nombres conocen los principales adblockers, estos tendrán que buscar otros métodos cuando se haya modificado el nombre de la biblioteca JavaScript o cuando los sitios hayan creado sus propias bibliotecas.

uBlock Origin, eficaz contra el CNAME cloaking en Firefox, ¿impotente contra el Server-Side Tagging?
Un paso por delante de los adblockers
La biblioteca JavaScript de Google Tag Manager se llama gtm.js, y se invoca con el identificador del contenedor: GTM-.... Por lo tanto, un adblocker puede apuntar fácilmente a estos nombres y bloquear la carga de esta biblioteca. Un sitio web podría decidir crear su propia biblioteca JavaScript, pero no es tan fácil.
Pero, de nuevo gracias a Simo Ahava, ahora es fácil elegir otro nombre para la biblioteca JavaScript gtm.js y ocultar el identificador del contenedor (ya no hace falta crear tu propia biblioteca JavaScript):
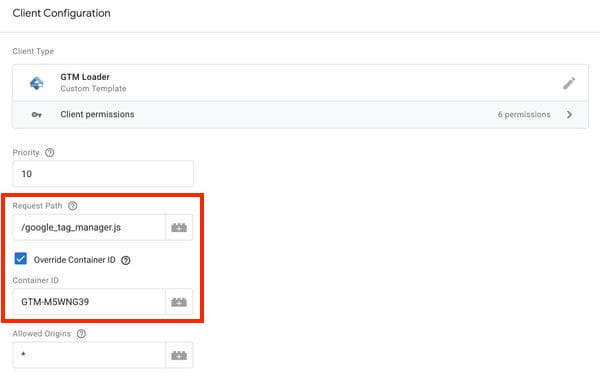
Vía el blog de Simo Ahava: con la plantilla "GTM Loader" de Simo, el sitio web puede renombrar la biblioteca JavaScript ("Request Path") y ocultar el identificador del contenedor ("Override Container ID" marcado, "Container ID" vacío).
Además, aunque los adblockers podían apuntar al proxy de Google, ahora un sitio web puede alojar el contenedor de servidor en otro lugar (en Amazon AWS, Microsoft Azure, OVH... o en su propia infraestructura). No es tan fácil, pero Google proporciona la imagen Docker y los pasos a seguir.
Así, Simo Ahava indica el procedimiento para desplegar el contenedor de servidor en Amazon AWS, mientras que Mark Edmondson detalla cómo desplegar el contenedor de servidor en Google Cloud Run (otro servicio de Google Cloud Platform, distinto de Google App Engine).
¿Cómo pueden reaccionar los adblockers?
El tema no es sencillo; aquí van algunas ideas, aunque no estoy seguro de que sean factibles:
- Detectar automáticamente estas llamadas "first-party" al servidor "proxy" a través de los parámetros de URL enviados. Solo que estos parámetros de URL cambiarán de un sitio a otro, en función de la biblioteca utilizada, de la página consultada, etc.
- Detectar la biblioteca JavaScript responsable de las llamadas al servidor "proxy" para bloquear su ejecución. Como hemos visto, este método no funcionará si el sitio web renombra la biblioteca de Google Tag Manager o desarrolla su propia biblioteca JavaScript.
- Bloquear los proxies, ¿a riesgo de bloquear funcionalidades esenciales de los sitios web? Además, este método no funciona si el sitio web decide alojar el contenedor de servidor en su propia infraestructura.
- No ejecutar nunca JavaScript en tu navegador, por ejemplo con la extensión NoScript, configurada de forma radical. Una opción eficaz, salvo que muchos sitios web dejarán de funcionar.
Filtrar tus datos personales en total opacidad
Aunque hoy en día muchos sitios web filtran tus datos personales, a menudo sin tu consentimiento, sigue siendo posible auditar los sitios, demostrar la violación del consentimiento y documentar las filtraciones. La CNIL podría, por ejemplo, hacer su trabajo y sancionar las infracciones. Nada de esto ocurre con el Server-Side Tagging: ahora un sitio puede, con toda facilidad:
- Dar una apariencia de consentimiento dejándote responder a un banner de consentimiento.
- Y, al mismo tiempo, filtrar tus datos personales a múltiples terceros, sin que un auditor externo pueda darse cuenta (solo verá la llamada "first-party" al servidor "proxy", sin saber si los datos personales se utilizan, se comparten o se revenden por detrás).
Tus datos en la nube de Google
Por defecto, el servidor "proxy" registra todas las solicitudes que recibe:
De forma predeterminada, App Engine registra información sobre cada una de las solicitudes (por ejemplo, la ruta de la solicitud, los parámetros de consulta, etc.) que recibe.
Pero los datos personales contenidos en estas solicitudes no son la única información que se filtra a Google. Igual que con el CNAME cloaking, las cookies asociadas al dominio del sitio consultado se envían al subdominio del servidor "proxy". Así, si las cookies de tu sesión están asociadas al dominio del sitio (y no a un subdominio distinto), se enviarán a la nube de Google.
Google declara que los datos alojados en su nube pertenecen al cliente, y no a Google. Aun así, tienes que confiar en Google.
Server-Side Tagging, probablemente pronto ampliamente adoptado
Aunque las soluciones Server-Side existían en el mercado desde hacía mucho tiempo, y aunque ya era posible desarrollar tu propio "proxy", el lanzamiento de la solución de Google tendrá probablemente un enorme impacto en la adopción del Server-Side Tagging:
- Google Tag Manager está presente en un número considerable de sitios web, es ultradominante.
- Google presenta esta versión como una evolución de las herramientas TMS, que mejora el rendimiento y la seguridad de los sitios web.
- Un gran argumento para los marketeros: filtrar tus datos personales a Facebook.
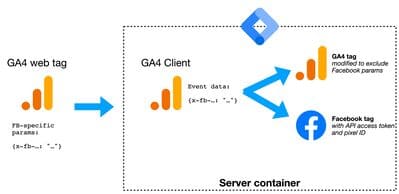
Una etiqueta de Google Analytics puede ocultar la filtración de tus datos personales a Facebook, ¡combo!
Aunque un cliente de Google Tag Manager pueda seguir utilizando la versión Client-Side, aunque la versión Server-Side todavía tenga límites (pocas bibliotecas de terceros, algunas soluciones serán difíciles de soportar, etc.), aunque aprender a usar la solución sea complejo e incluso aunque a menudo sea de pago (factura de Google App Engine por el servidor "proxy"), podemos apostar a que los clientes de Google Tag Manager migrarán progresivamente a esta versión.
Esquivar los adblockers y otras protecciones del navegador, un argumento de venta
Como hemos visto, Google no explica el motivo para crear un subdominio del sitio web destinado a su servidor "proxy":
El despliegue de etiquetado del lado del servidor predeterminado se aloja en un dominio de App Engine. Te recomendamos que modifiques el despliegue para utilizar en su lugar un subdominio de tu sitio web.
No le hace falta: esquivar las protecciones del navegador y los adblockers ya ha sido catalogado como "beneficio" en numerosas publicaciones:
- "Server-side Tagging In Google Tag Manager" de Simo Ahava: el artículo señala como beneficio poder esquivar las limitaciones de Safari respecto a la vida útil de las cookies JavaScript. Para su honor, el autor no quiere dar detalles sobre el hecho de que el Server-Side Tagging permite esquivar los adblockers, e indica que la recopilación de datos debe hacerse tras obtener el consentimiento.
- "GTM Server Side – ¿la evolución natural de tu tagging?" de Converteo. El artículo enumera entre las ventajas el poder esquivar las limitaciones de los navegadores como las de Safari y Firefox, así como esquivar los adblockers.
- "Introduction to Google Tag Manager Server-side Tagging", del blog Analytics Mania. También aquí, esquivar las limitaciones de los navegadores y los adblockers se enumera como beneficio.
- "Google introduce el tagging del lado del servidor, ¿una buena noticia?" de Nicolas Jaimes en el JDN. El enfoque del artículo es la publicidad y, por tanto, esquivar las protecciones del navegador se enumera como beneficio (aunque, de momento, la falta de bibliotecas de terceros hace que el Server-Side Tagging siga siendo complejo de implementar).
Por desgracia, es muy probable que muchos sitios se dejen seducir también por estos "beneficios", además de por las mejoras en rendimiento, seguridad y control. La imposibilidad de auditar los sitios web será también una gran pérdida para los defensores de la privacidad. Esperemos que los navegadores y los adblockers encuentren contramedidas para que los internautas preocupados por su privacidad puedan seguir defendiéndose.